最近因為工作需要,站長又重新複習最不屑的 PHP,所以就找了個題目練練手感,順便也接續之前的 Regular Expression 話題
假設你有一個神奇演算法可以推算股市的走向,但是你需要每隔一段時間就把股價記錄下來好進行統計分析,假設你的資料是從
kimo 來的好了:
kimo 來的好了:


很顯然,kimo 提供的網頁適合給人看,給程式分析就顯得太過複雜,再說我們只對下面圈起來的部份有興趣

所以說,理想的情形應該是把這表格內的股價資訊抽取出來,存成簡單的文字檔格式,一般來說存成 csv 是最方便的,因為 Excel
也可以很輕鬆的讀取
也可以很輕鬆的讀取
ok!讓我們開始吧,就以半導體類的股價來實驗看看,

URL query string 中的數字很可疑,多 reload 幾次 getstock.php,您會發現每次連到半導體類股價的 URL 都不太一樣?


姑且不論 kimo
這樣作的原因為何,為了保險起見還是應該以 getstock.php 中的為準,所以我們的程式第一步就是要從 getstock.php 中取得正確的 URL,再次按右鍵觀察 html 原始碼:
這樣作的原因為何,為了保險起見還是應該以 getstock.php 中的為準,所以我們的程式第一步就是要從 getstock.php 中取得正確的 URL,再次按右鍵觀察 html 原始碼:

是我們的老朋友 BIG5,這就容易了
因為不知道把「半導體」三個字塞進 regex 裡面會不會有副作用,所以轉成 \xA5\x62\xBE\xC9\xC5\xE9 比較保險,再把之前 HTML to e-mail 一文中的 <img>...</img> Regex pattern
替換成 <a href="...">...</a> 就好了
替換成 <a href="...">...</a> 就好了

因為 PHP 採用的是 PCRE ,所以我們把 Atomic Group 替換成 Possessive Quantifiers,效果一樣,但是 pattern 內可以省掉很多括號(注意,這時候縮短 pattern
才有實質意義)
才有實質意義)
另外還要注意的是,URL query string 中的空白要替換成 '+',這才符合 RFC3986 的規定,綜合以上討論得出的原始碼就是:
<?php function get_stock_class_url($stock_class, &$url) { $curl = curl_init(); curl_setopt($curl, CURLOPT_URL, "http://tw.stock.yahoo.com/h/getclass.php"); // 以字串傳回結果 curl_setopt($curl, CURLOPT_RETURNTRANSFER, TRUE); // 支援header重導向(僅3次) curl_setopt($curl, CURLOPT_FOLLOWLOCATION, TRUE); curl_setopt($curl, CURLOPT_MAXREDIRS, 3); // 設定超過10秒就算失敗 curl_setopt($curl, CURLOPT_TIMEOUT, 10); // search URL in <a>XXX</a> $result = preg_match('/<a' . '(?:\s++(?!href)[A-Z][-:A-Z0-9]*+(?:\s*+=\s*+(?:"[^"]*+"|\'[^\']*+\'|[-.:\w]++))?+)*+' . '\s++href\s*+=\s*+(?>"([^"]*+)"|\'([^\']*+)\'|([-.:\w]++))' . '[^<>]*+>' . $stock_class . '<\/a>/ix', curl_exec($curl), $matches); curl_close($curl); if($result <= 0) return false; for($i = 1; $i < count($matches); $i++) { if(!isset($matches[$i]) || strlen($matches[$i]) <= 0) continue; $pos = strrpos($matches[$i], "?"); if($pos === FALSE) continue; $url = 'http://tw.stock.yahoo.com' . str_replace(" ", "+", $matches[$i]); return true; } return false; } // '\xA5\x62\xBE\xC9\xC5\xE9' = 半導體 if(get_stock_class_url('\xA5\x62\xBE\xC9\xC5\xE9', $url)) { echo "success!\n"; } else { echo "fail!\n"; } ?>
有了正確的 URL,現在來嘗試抽取表格資訊吧!但是 table 只有一個嗎?再次偷看 kimo 原始碼:



有一堆 table,其中某些可能只是拿來排版用的(沒想到 kimo 還在用這招XD),我們有興趣的 table 裡面有什麼資訊可以判別呢?首先想到的是 tag id,
很抱歉沒有,這邊找不到什麼優雅的解法,就直接判斷 table 裡面有沒有「股票代號」這四個字吧!
很抱歉沒有,這邊找不到什麼優雅的解法,就直接判斷 table 裡面有沒有「股票代號」這四個字吧!

這邊站長偷懶一下,直接把所有的 table 抽取出來(不包含巢狀 table),然後逐個搜尋裡面看看有沒有「股價資訊」這四個字,要把所有的 table
抽取出來,用的 pattern 就是:
抽取出來,用的 pattern 就是:
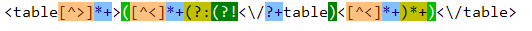
Regex 大師 Jeffrey E.F. Friedl 認為,當文字具備以下結構時可以用 unrolling 技巧優化:
opening normal* (special normal*)* closing
最簡單的例子算是 domain name:

因為這裡的 special part 只有一個字元「.」,您可能還沒什麼感覺,再看看 double quoted string:

比較有感覺了吧?同樣的 html tag 也具備這種特性,您可以自行推導一下,這樣作最大的優點是:
- 不須要用到多選分支
- 減少進出 group
所以比對的次數會減少一大半,再配合 Atomic Group or Possessive Quantifiers,差不多就是把油門踩到底了 (^_^)
找到需要的 table 之後,接下來就是拆解 table,有稍微寫過 html 的人都知道表格的組成是:

所以把拆解 table 就是把上面的 pattern 內的 table 替換成 tr, td,重複作兩次而已!最後得到的 source code 就是:
<?php function get_stock_class_url($stock_class, &$url) { $curl = curl_init(); curl_setopt($curl, CURLOPT_URL, "http://tw.stock.yahoo.com/h/getclass.php"); // 以字串傳回結果 curl_setopt($curl, CURLOPT_RETURNTRANSFER, TRUE); // 支援header重導向(僅3次) curl_setopt($curl, CURLOPT_FOLLOWLOCATION, TRUE); curl_setopt($curl, CURLOPT_MAXREDIRS, 3); // 設定超過10秒就算失敗 curl_setopt($curl, CURLOPT_TIMEOUT, 10); // search URL in <a>XXX</a> $result = preg_match('/<a' . '(?:\s++(?!href)[A-Z][-:A-Z0-9]*+(?:\s*+=\s*+(?:"[^"]*+"|\'[^\']*+\'|[-.:\w]++))?+)*+' . '\s++href\s*+=\s*+(?>"([^"]*+)"|\'([^\']*+)\'|([-.:\w]++))' . '[^<>]*+>' . $stock_class . '<\/a>/ix', curl_exec($curl), $matches); curl_close($curl); if($result <= 0) return false; for($i = 1; $i < count($matches); $i++) { if(!isset($matches[$i]) || strlen($matches[$i]) <= 0) continue; $pos = strrpos($matches[$i], "?"); if($pos === FALSE) continue; $url = 'http://tw.stock.yahoo.com' . str_replace(" ", "+", $matches[$i]); return true; } return false; } function get_stock_class_table($url) { $curl = curl_init(); curl_setopt($curl, CURLOPT_URL, $url); // 以字串傳回結果 curl_setopt($curl, CURLOPT_RETURNTRANSFER, TRUE); // 支援header重導向(僅3次) curl_setopt($curl, CURLOPT_FOLLOWLOCATION, TRUE); curl_setopt($curl, CURLOPT_MAXREDIRS, 3); // 假裝從 http://tw.stock.yahoo.com/h/getclass.php click URL curl_setopt($curl, CURLOPT_REFERER, 'http://tw.stock.yahoo.com/h/getclass.php'); // 設定超過10秒就算失敗 curl_setopt($curl, CURLOPT_TIMEOUT, 10); // 取得 html 順便搜尋 <table>...</table> $match_result = preg_match_all('/<table[^>]*+>([^<]*+(?:(?!<\/?+table)<[^<]*+)*+)<\/table>/i', curl_exec($curl), $table_matches, PREG_SET_ORDER); curl_close($curl); if($match_result === FALSE || $match_result <= 0) return false; // 找出內含股票代號的 table for($i = 0; $i < count($table_matches); $i++) { if(strpos($table_matches[$i][1], '股票代號') > 0) break; } if(count($table_matches) <= $i) return false; // search <tr>...</tr> $match_result = preg_match_all('/<tr[^>]*+>([^<]*+(?:(?!<\/?+tr)<[^<]*+)*+)<\/tr>/ix', $table_matches[$i][1], $tr_matches, PREG_SET_ORDER); if($match_result === FALSE || $match_result <= 0) return false; // search <td>...</td> and print out for($i = 0; $i < count($tr_matches); $i++) { $match_result = preg_match_all('/<td[^>]*+>([^<]*+(?:(?!<\/?+td)<[^<]*+)*+)<\/td>/ix', $tr_matches[$i][1], $td_matches, PREG_SET_ORDER); if($match_result === FALSE || $match_result <= 0) continue; // 移除 <td>...</td> 內的 HTML tag 與換行符號 echo trim(str_replace("\n", "", preg_replace('/<[^>]++>/', '', $td_matches[1][1]))); for($j = 2; $j < count($td_matches)-1; $j++) { echo ',' . trim(preg_replace("/[\n,]/", '', preg_replace('/<[^>]++>/', '', $td_matches[$j][1]))); } echo "\n"; } return true; } // '\xA5\x62\xBE\xC9\xC5\xE9' = 半導體 if(get_stock_class_url('\xA5\x62\xBE\xC9\xC5\xE9', $url)) { if(!get_stock_class($url)) { echo "get_stock_class() fail!\n"; die(); } } else { echo "get_stock_class_url() fail!\n"; } ?>
用 Excel 來欣賞一下成果

心得
本篇對於很多人來說應該是相當實用的,例如您可以寫個 MSN 機器人,發現股票掉到停損點時通知您趕緊賣出;但是請注意,假如您真的 24hours 去 kimo 撈資料,您可能會被當成 hacker 因而吃上官司,小心喔!
另外,用 PHP 寫網路機器人也已經有了專書,根據該作者的建議用 TidyHTML 分析 HTML 是比較好的選擇,您可以參考看看,最後祝您使用愉快,Good Luck!
您的介紹真是用心,
回覆刪除我一定要把這個學起來,感恩。